XQuAD Dataset Papers With Code
Por um escritor misterioso
Last updated 03 outubro 2024

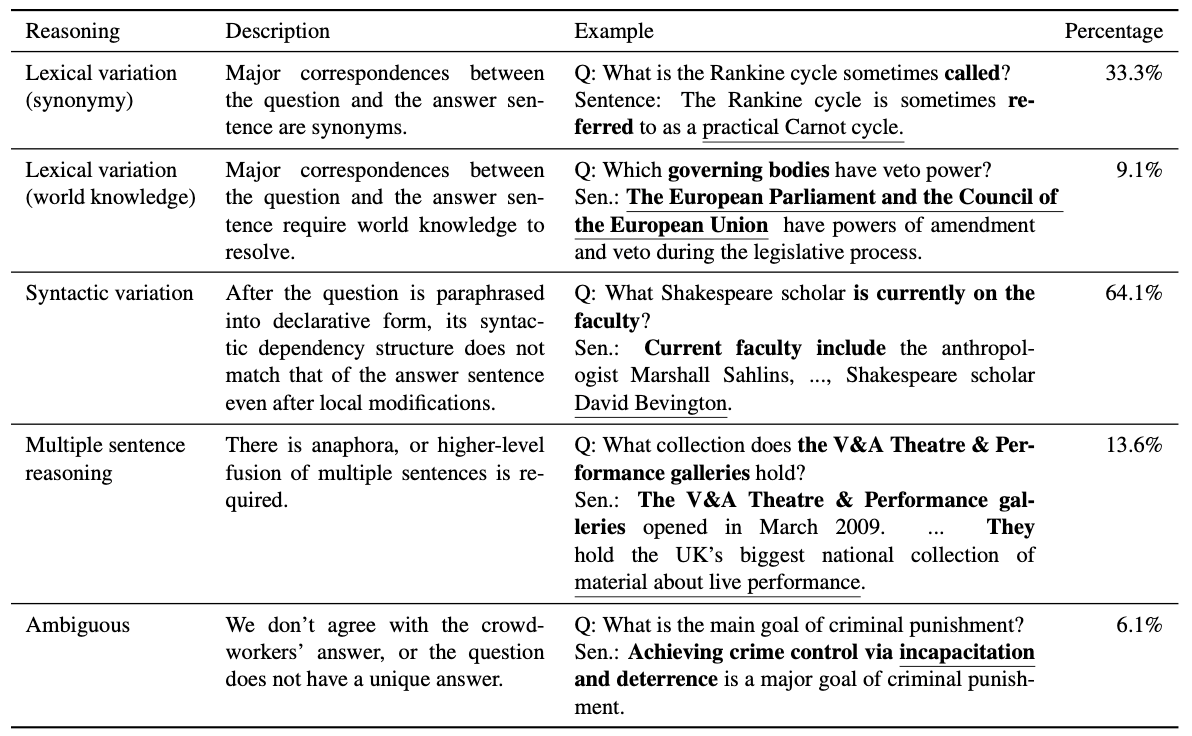
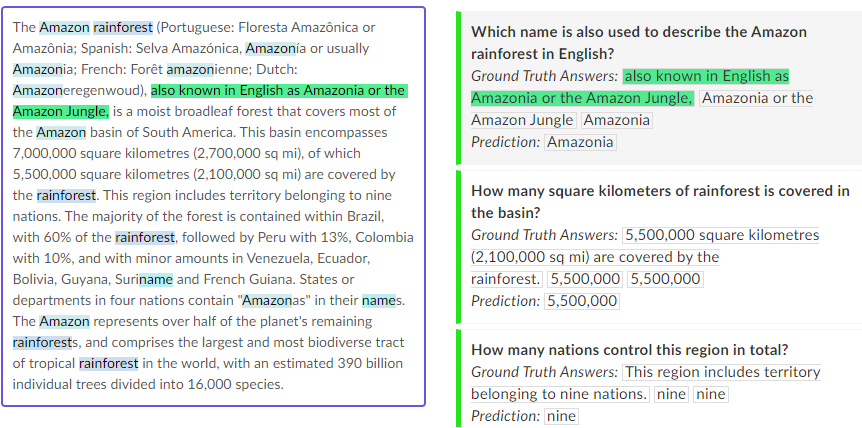
XQuAD (Cross-lingual Question Answering Dataset) is a benchmark dataset for evaluating cross-lingual question answering performance. The dataset consists of a subset of 240 paragraphs and 1190 question-answer pairs from the development set of SQuAD v1.1 (Rajpurkar et al., 2016) together with their professional translations into ten languages: Spanish, German, Greek, Russian, Turkish, Arabic, Vietnamese, Thai, Chinese, and Hindi. Consequently, the dataset is entirely parallel across 11 languages.

Machine Learning Datasets

F1 score on XQuAD for XLM-R model finetuned on SQuAD en
The Quick Guide to SQuAD. All the basic information you need to
End to End Question-Answering System Using NLP and SQuAD Dataset

UQuAD1.0: Development of an Urdu Question Answering Training Data

MED Dataset Papers With Code

How SIGNAL IDUNA operationalizes machine learning projects on AWS

PDF] CodeQA: A Question Answering Dataset for Source Code
image195.png

Spoken-SQuAD Dataset

CovidQA Dataset Papers With Code
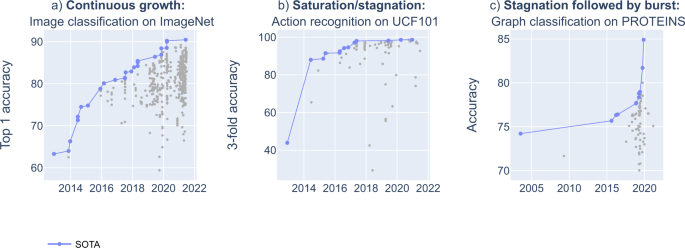
Mapping global dynamics of benchmark creation and saturation in

Automatic Spanish Translation of SQuAD Dataset for Multi-lingual

How to Answer Questions with Machine Learning
Recomendado para você
-
 ME6016 ADVANCED I.C ENGINES - SHORT QUESTIONS AND ANSWERS03 outubro 2024
ME6016 ADVANCED I.C ENGINES - SHORT QUESTIONS AND ANSWERS03 outubro 2024 -
 Top IC Engine Interview Questions & Answers 2023 - MindMajix03 outubro 2024
Top IC Engine Interview Questions & Answers 2023 - MindMajix03 outubro 2024 -
 Gas Turbine Interview Questions and Answers - Power Plant03 outubro 2024
Gas Turbine Interview Questions and Answers - Power Plant03 outubro 2024 -
 STCW_Test_-Answers_Report_Management Questions and answers., Exams Health sciences03 outubro 2024
STCW_Test_-Answers_Report_Management Questions and answers., Exams Health sciences03 outubro 2024 -
![IC Engine Cycles MCQ [Free PDF] - Objective Question Answer for IC Engine Cycles Quiz - Download Now!](https://storage.googleapis.com/tb-img/production/19/06/RRB_JE_ME_49_15Q_TE_CH_4_HIndi%20-%20Final_Diag%28Shashi%29_images_Q7.PNG) IC Engine Cycles MCQ [Free PDF] - Objective Question Answer for IC Engine Cycles Quiz - Download Now!03 outubro 2024
IC Engine Cycles MCQ [Free PDF] - Objective Question Answer for IC Engine Cycles Quiz - Download Now!03 outubro 2024 -
 Parts of a Small Engine Student Workbook and Instructor Script/Key03 outubro 2024
Parts of a Small Engine Student Workbook and Instructor Script/Key03 outubro 2024 -
 Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu03 outubro 2024
Valid Salesforce Networks Web Services Education-Cloud-Consultant Dumps pdf 2023 by Olivia James - Issuu03 outubro 2024 -
![Aug 11, 2023] C_MDG_1909 Dumps PDF and Test Engine Exam Questions - Actual4test [Q47-Q64]](https://www.actual4test.com/uploads/imgs/C_MDG_1909-banner_a244691_c84e8557f5e72d4181ff046a93acfbf2.jpg) Aug 11, 2023] C_MDG_1909 Dumps PDF and Test Engine Exam Questions - Actual4test [Q47-Q64]03 outubro 2024
Aug 11, 2023] C_MDG_1909 Dumps PDF and Test Engine Exam Questions - Actual4test [Q47-Q64]03 outubro 2024 -
 NODE.JS Interview Questions & Answers - CodeWithCurious03 outubro 2024
NODE.JS Interview Questions & Answers - CodeWithCurious03 outubro 2024 -
 Pin on Stuff to buy03 outubro 2024
Pin on Stuff to buy03 outubro 2024
você pode gostar
-
 Vampire: The Masquerade® - Bloodlines™ 2 Coming Soon - Epic Games03 outubro 2024
Vampire: The Masquerade® - Bloodlines™ 2 Coming Soon - Epic Games03 outubro 2024 -
 EMILIA CLARKE NA NOVA SÉRIE DE GAME OF THRONES? - HOUSE OF THE DRAGON03 outubro 2024
EMILIA CLARKE NA NOVA SÉRIE DE GAME OF THRONES? - HOUSE OF THE DRAGON03 outubro 2024 -
 Melhores jogos de futebol pra Xbox One - Blog da Lu - Magazine Luiza03 outubro 2024
Melhores jogos de futebol pra Xbox One - Blog da Lu - Magazine Luiza03 outubro 2024 -
 Monster Trucks Dodge C-3 #16 by DipperBronyPines98 on DeviantArt03 outubro 2024
Monster Trucks Dodge C-3 #16 by DipperBronyPines98 on DeviantArt03 outubro 2024 -
Camiseta Infantil Juvenil Dragon Ball Z Goku Anime Desenho USADA Tamanho 14 Chumbo03 outubro 2024
-
 Clancy Coat of Arms Vintage Poster03 outubro 2024
Clancy Coat of Arms Vintage Poster03 outubro 2024 -
 blox fruit melhor fruta para farmar no 203 outubro 2024
blox fruit melhor fruta para farmar no 203 outubro 2024 -
 18 Best Games of All Time03 outubro 2024
18 Best Games of All Time03 outubro 2024 -
Ziluu (巨) · GitHub03 outubro 2024
-
 Vestido Casa de Abelha Rosa Xadrez Ponto Smock com Short - Loja03 outubro 2024
Vestido Casa de Abelha Rosa Xadrez Ponto Smock com Short - Loja03 outubro 2024

