PDF] Near-Synonym Choice using a 5-gram Language Model
Por um escritor misterioso
Last updated 10 novembro 2024
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://d3i71xaburhd42.cloudfront.net/981fec6d9d4b45c2f0f4d80512fe0cf56419b8b1/10-Table3-1.png)
An unsupervised statistical method for automatic choice of near-synonyms is presented and compared to the stateof-the-art and it is shown that this method outperforms two previous methods on the same task. In this work, an unsupervised statistical method for automatic choice of near-synonyms is presented and compared to the stateof-the-art. We use a 5-gram language model built from the Google Web 1T data set. The proposed method works automatically, does not require any human-annotated knowledge resources (e.g., ontologies) and can be applied to different languages. Our evaluation experiments show that this method outperforms two previous methods on the same task. We also show that our proposed unsupervised method is comparable to a supervised method on the same task. This work is applicable to an intelligent thesaurus, machine translation, and natural language generation.
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://upload.wikimedia.org/wikipedia/commons/0/00/Space_sustainability_urgency_in_earth_orbits_white.png)
Space debris - Wikipedia
Language Model Concept behind Word Suggestion Feature, by Vitou Phy
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://media.springernature.com/m685/springer-static/image/art%3A10.1038%2Fs41586-023-06291-2/MediaObjects/41586_2023_6291_Fig1_HTML.png)
Large language models encode clinical knowledge
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://venngage-wordpress.s3.amazonaws.com/uploads/2020/06/how-to-make-an-infographic-blog-header.png)
How to Make an Infographic in Under 1 Hour (2023 Guide) - Venngage
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://www.apa.org/images/inclusive-language-guide-header_tcm7-300244.jpg)
Inclusive Language Guide
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://i.ytimg.com/vi/JKiPMA-H608/hqdefault.jpg)
Class 10 Maths Chapter 2 Polynomials MCQs (With Answers)
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://media.springernature.com/lw685/springer-static/image/chp%3A10.1007%2F978-981-99-1999-4_2/MediaObjects/533412_1_En_2_Fig5_HTML.png)
N-Gram Language Model
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://www.kdnuggets.com/wp-content/uploads/agarwal_ngram_language_modeling_natural_language_processing_2.png)
N-gram Language Modeling in Natural Language Processing - KDnuggets
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://ecdn.teacherspayteachers.com/thumbitem/Synonyms-and-Antonyms-Resources-Common-Core-Supplement-L51c-and-d-063342300-1380410816-1516287085/original-901740-1.jpg)
Synonyms and Antonyms Resources {Common Core Supplement (L.5.5c)}
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://www.pnas.org/cms/asset/b7a58b9f-c5f3-4c4f-9708-c9ec093d8919/keyimage.jpg)
One model for the learning of language
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://www.questionpro.com/blog/wp-content/uploads/2018/04/What-is-Market-Research.jpg)
Market Research: What it Is, Methods, Types & Examples
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://miro.medium.com/v2/resize:fit:1228/1*BNrYUIi-hGFTeBnMy0sesg.png)
N-gram language models. Part 1: The unigram model, by Khanh Nguyen, MTI Technology
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://images.sample.net/wp-content/uploads/2022/10/Synonym-Challenge.jpg)
Sample Synonym, PDF
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://pub.mdpi-res.com/applsci/applsci-10-05996/article_deploy/html/images/applsci-10-05996-g001.png?1598708374)
Applied Sciences, Free Full-Text
![PDF] Near-Synonym Choice using a 5-gram Language Model](https://cdn.britannica.com/86/150486-050-3EBC3516/MyPlate-guidelines-food-groups-sections-section-plate-2011.jpg)
Human nutrition, Importance, Essential Nutrients, Food Groups, & Facts
Recomendado para você
-
 MISTAKE Synonyms: 116 Similar and Opposite Words10 novembro 2024
MISTAKE Synonyms: 116 Similar and Opposite Words10 novembro 2024 -
 Function Meaning- something that works great Synonym- works good conditions great Antonym- bad conditions Story sentence-It takes lots of practice to learn. - ppt download10 novembro 2024
Function Meaning- something that works great Synonym- works good conditions great Antonym- bad conditions Story sentence-It takes lots of practice to learn. - ppt download10 novembro 2024 -
The Definition of a Mistake10 novembro 2024
-
 Unit 10 Level D by seangilbertpay10 novembro 2024
Unit 10 Level D by seangilbertpay10 novembro 2024 -
 Synonym Antonym Bingo10 novembro 2024
Synonym Antonym Bingo10 novembro 2024 -
 Synonyms of By mistake, By mistake ka synonyms, similar word of By mistake10 novembro 2024
Synonyms of By mistake, By mistake ka synonyms, similar word of By mistake10 novembro 2024 -
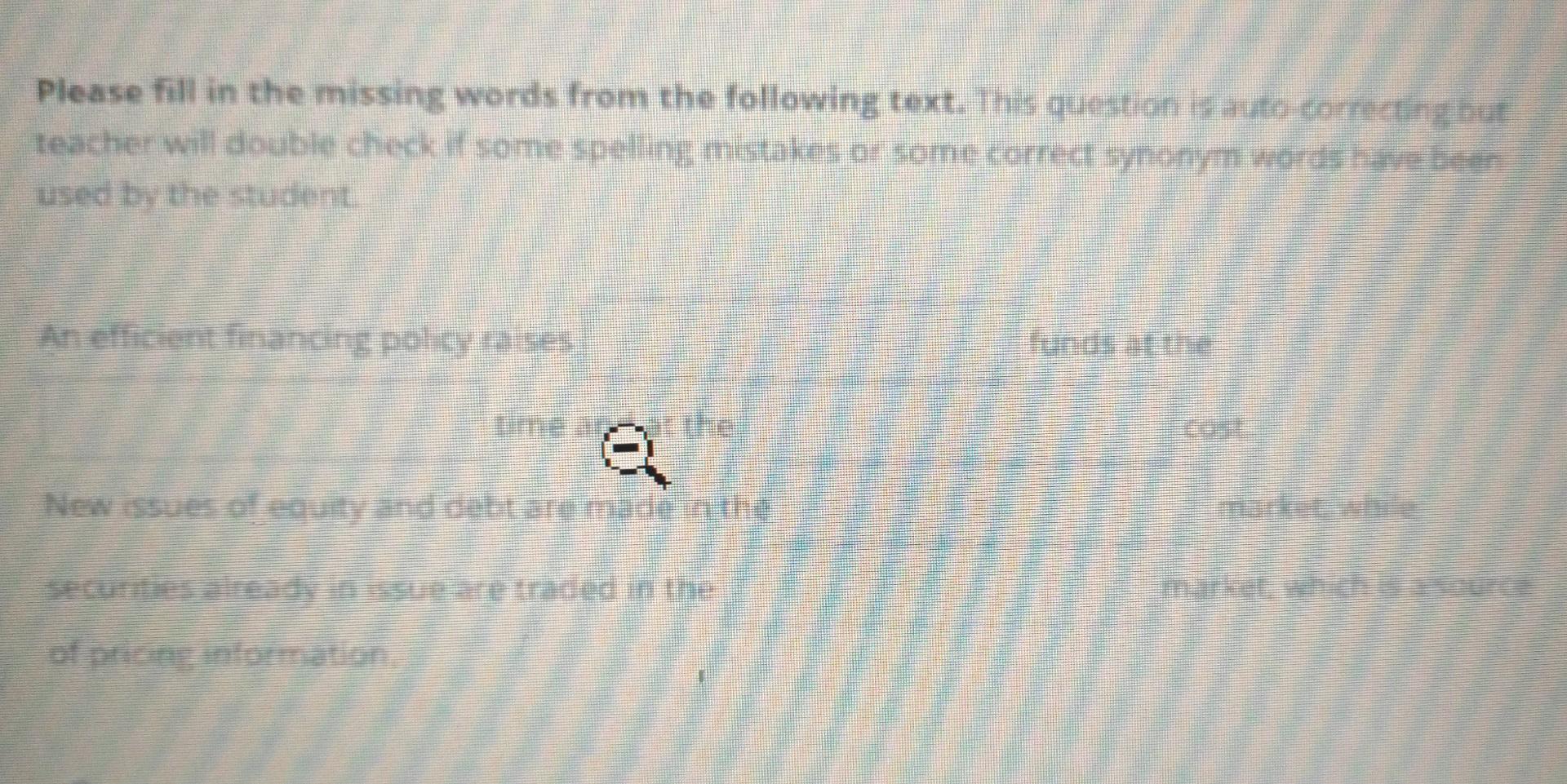 Solved Please fill in the missing words from the following10 novembro 2024
Solved Please fill in the missing words from the following10 novembro 2024 -
 Nice ways to say you're wrong in English - The London School of English10 novembro 2024
Nice ways to say you're wrong in English - The London School of English10 novembro 2024 -
 Most Common Synonym Words10 novembro 2024
Most Common Synonym Words10 novembro 2024 -
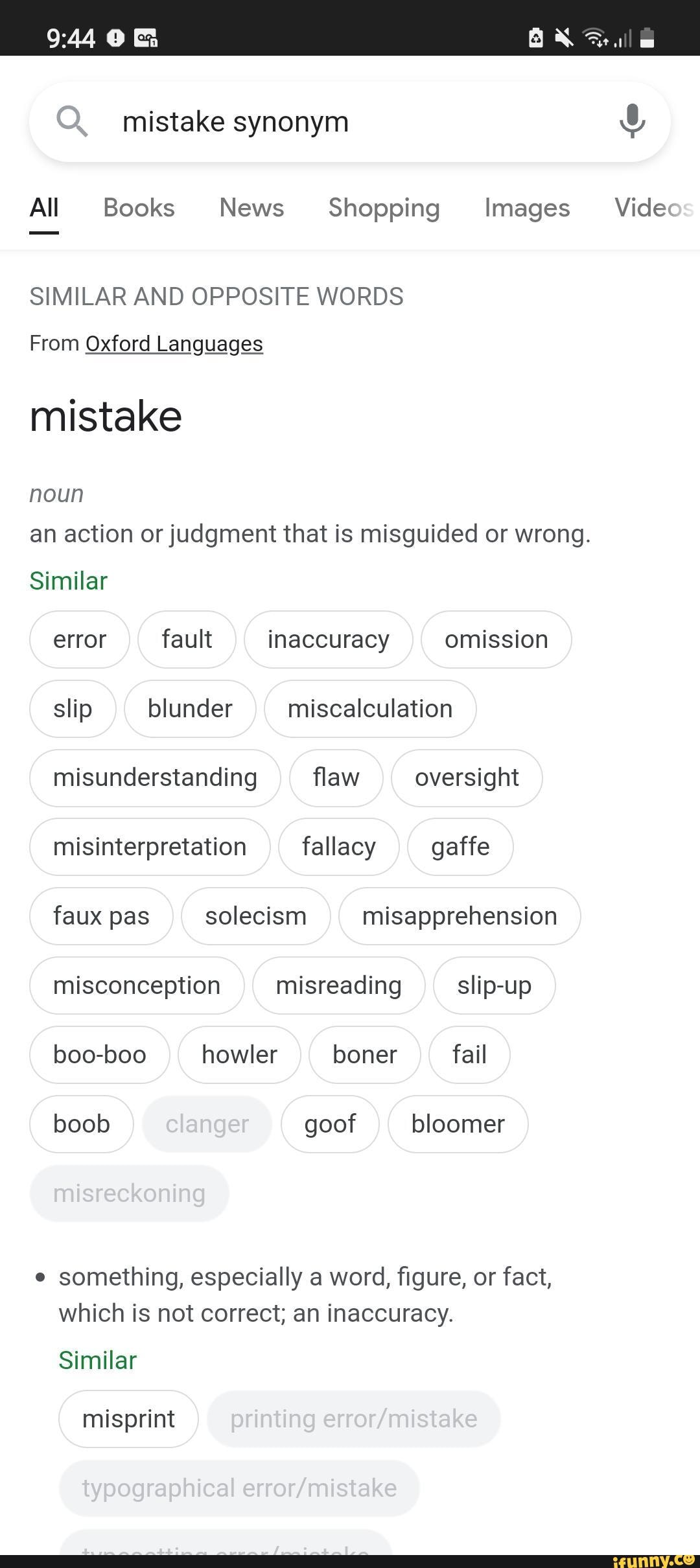 Mistake synonym all All Books News Shopping Images Videos SIMILAR AND OPPOSITE WORDS From Oxford Languages10 novembro 2024
Mistake synonym all All Books News Shopping Images Videos SIMILAR AND OPPOSITE WORDS From Oxford Languages10 novembro 2024
você pode gostar
-
 Lista de todas as ligas e clubes de FIFA 23 - Electronic Arts10 novembro 2024
Lista de todas as ligas e clubes de FIFA 23 - Electronic Arts10 novembro 2024 -
 Os 10 Pokémon tipo Dragão mais fortes da franquia, ranqueados10 novembro 2024
Os 10 Pokémon tipo Dragão mais fortes da franquia, ranqueados10 novembro 2024 -
MyAnimeList.net - Koe no Katachi is now Kyoto Animation's most popular anime of all time, passing long-time #1 Clannad! 🌸 /producer/210 novembro 2024
-
/i.s3.glbimg.com/v1/AUTH_ba3db981e6d14e54bb84be31c923b00c/internal_photos/bs/2021/r/3/y8k9XUSByBjoISD9gUhQ/2019-07-22-jogos-de-manicure.jpg) Jogos de unha: 5 sites para você brincar de manicure online10 novembro 2024
Jogos de unha: 5 sites para você brincar de manicure online10 novembro 2024 -
 Boneca Polly Pocket O Melhor Carro de Todos Mattel BCY59 - Carrefour - Carrefour10 novembro 2024
Boneca Polly Pocket O Melhor Carro de Todos Mattel BCY59 - Carrefour - Carrefour10 novembro 2024 -
 filtro de mine and dash|TikTok Search10 novembro 2024
filtro de mine and dash|TikTok Search10 novembro 2024 -
 O Gambito da Rainha faz disparar vendas de xadrez e livros sobre o10 novembro 2024
O Gambito da Rainha faz disparar vendas de xadrez e livros sobre o10 novembro 2024 -
 IFBA/Jequié define datas de matrícula do PRONATEC - Blog Marcos Frahm10 novembro 2024
IFBA/Jequié define datas de matrícula do PRONATEC - Blog Marcos Frahm10 novembro 2024 -
 Série “Sex Education” ajuda agência francesa a responder a perguntas dos adolescentes10 novembro 2024
Série “Sex Education” ajuda agência francesa a responder a perguntas dos adolescentes10 novembro 2024 -
) Caminhão de Brinquedo Superfrota Bitrem Bombeiro Tanque - Poliplac10 novembro 2024
Caminhão de Brinquedo Superfrota Bitrem Bombeiro Tanque - Poliplac10 novembro 2024
