Mastering TicTacToe with AlphaZero
Por um escritor misterioso
Last updated 10 novembro 2024
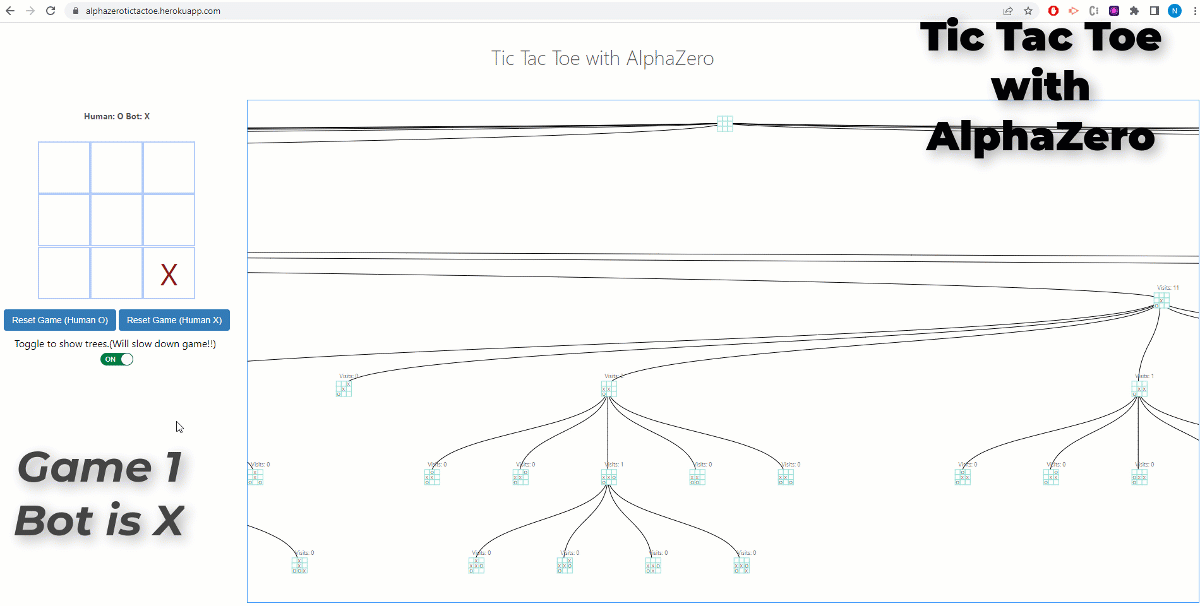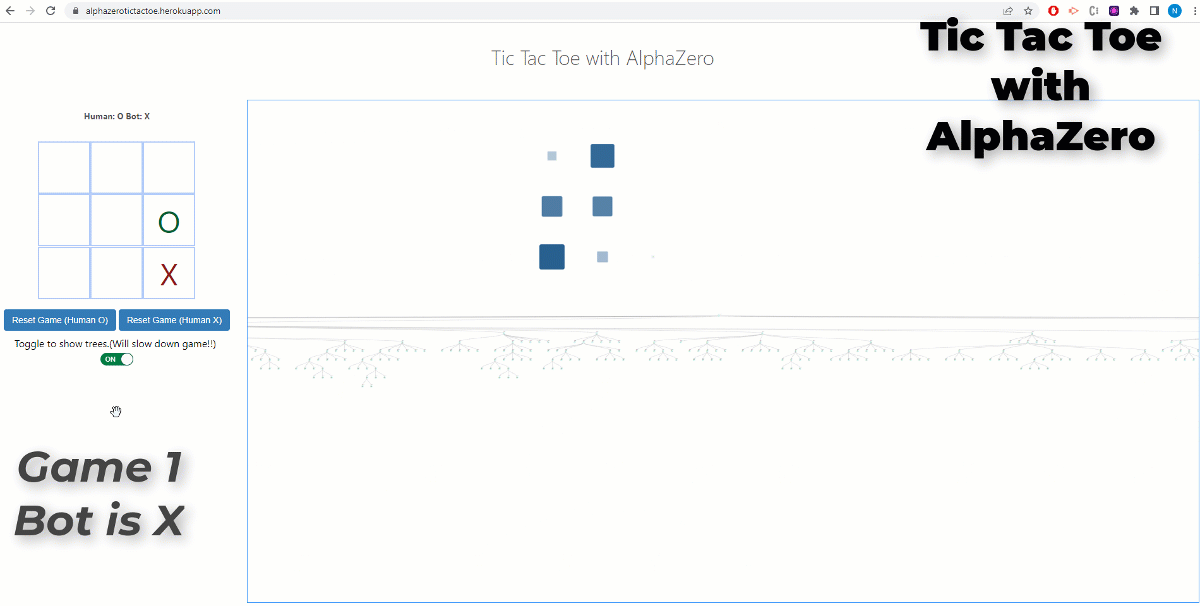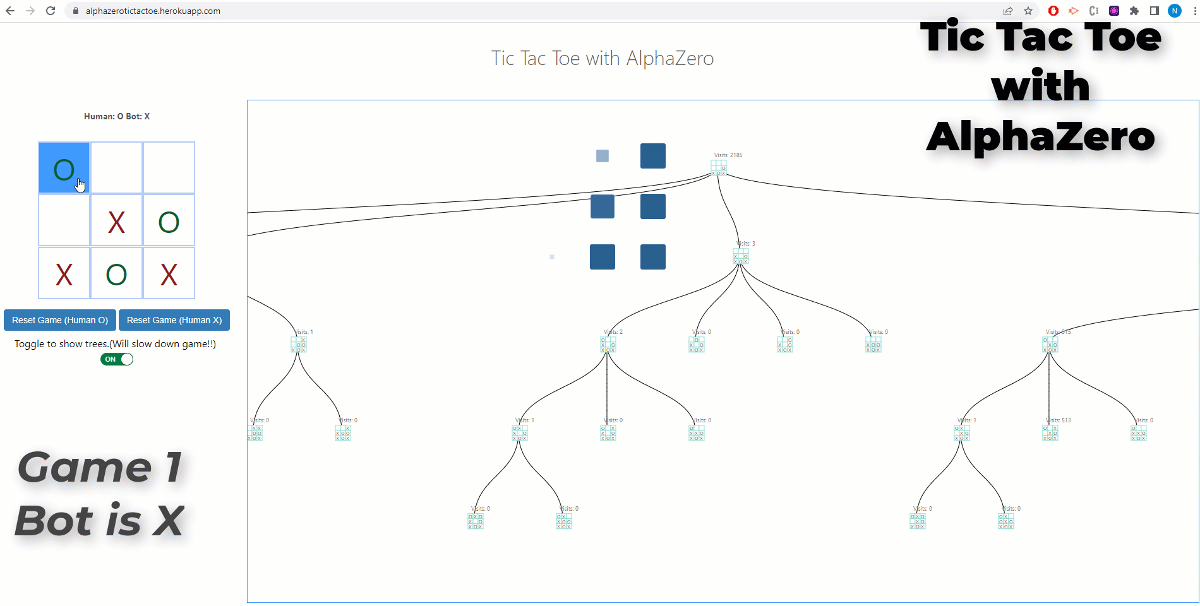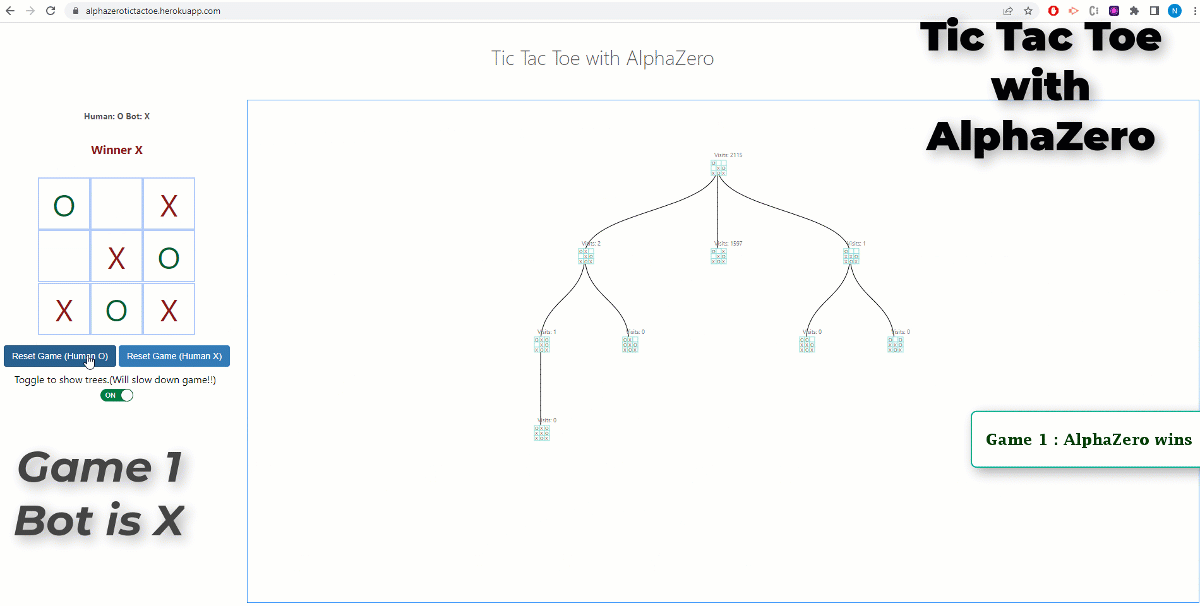
AlphaZero (or it’s more famous predecessor AlphaGo) made one of the most famous breakthroughs in the field of AI. Being able to achieve superhuman performance in the games of chess, shogi and go…

AlphaGo Zero – How and Why it Works – Tim Wheeler

Figure 8 from AlphaGo and Monte Carlo tree search: The simulation optimization perspective

Multiplayer AlphaZero – arXiv Vanity

AlphaZero: Innovating AI through Self-Play - Machine Learning Tutorial — Eightify

Multiplayer AlphaZero – arXiv Vanity

Using MuZero's Tree Search To Find Optimal Tic-Tac-Toe Strategy in a Spreadsheet
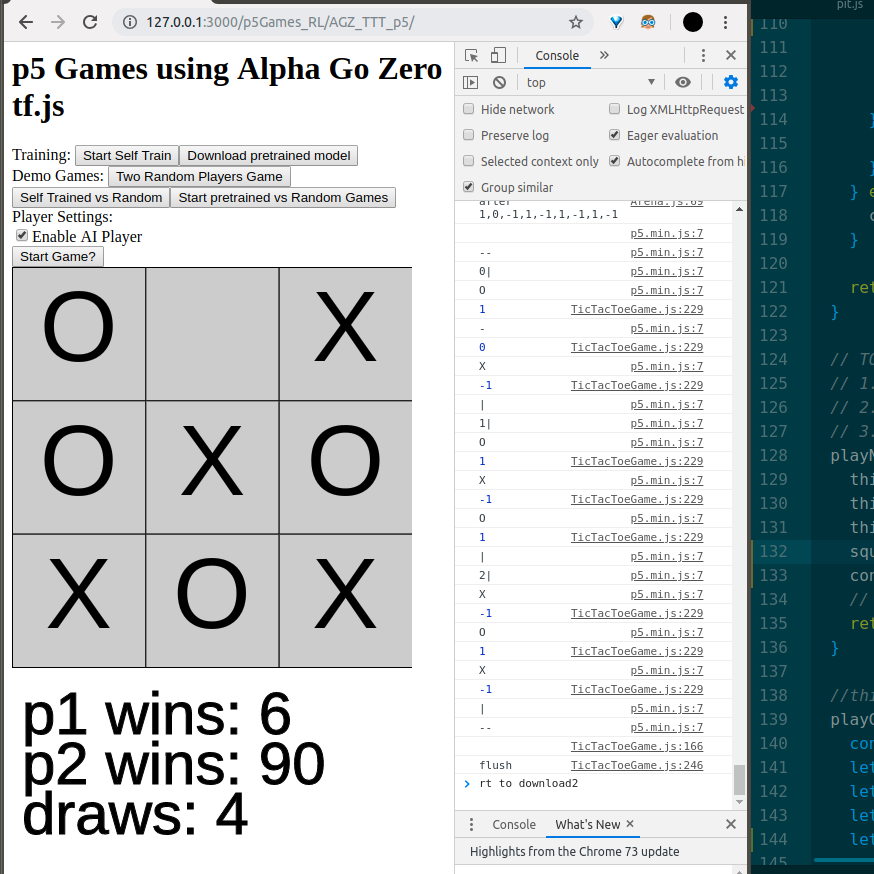
Alpha Zero General playing Tic Tac Toe in p5 using tf.js — J. August Luhrs
Chess algorithm—AlphaZero — TOK RESOURCE.ORG

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero, trained to master Tic-Tac-Toe and Four in a row

GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero, trained to master Tic-Tac-Toe and Four in a row

Using MuZero's Tree Search To Find Optimal Tic-Tac-Toe Strategy in a Spreadsheet

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play
tictactoe · GitHub Topics · GitHub
Recomendado para você
-
 The future is here – AlphaZero learns chess10 novembro 2024
The future is here – AlphaZero learns chess10 novembro 2024 -
 AlphaZero, Vladimir Kramnik and reinventing chess10 novembro 2024
AlphaZero, Vladimir Kramnik and reinventing chess10 novembro 2024 -
 Google's AlphaZero Destroys Stockfish In 100-Game Match10 novembro 2024
Google's AlphaZero Destroys Stockfish In 100-Game Match10 novembro 2024 -
 AlphaGo Zero Explained In One Diagram, by David Foster, Applied Data Science10 novembro 2024
AlphaGo Zero Explained In One Diagram, by David Foster, Applied Data Science10 novembro 2024 -
GitHub - AlSaeed/AlphaZero: An Implementation of the AlphaZero Paper10 novembro 2024
-
 AI Summary: Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search10 novembro 2024
AI Summary: Finding Increasingly Large Extremal Graphs with AlphaZero and Tabu Search10 novembro 2024 -
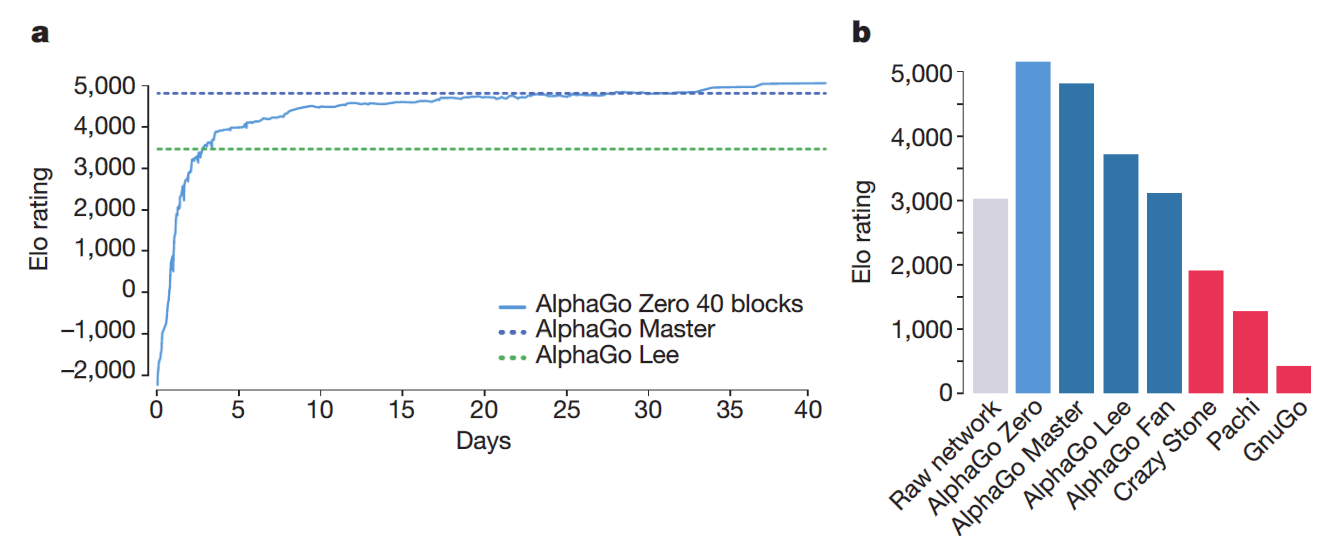 How DeepMind's AlphaGo Became the World's Top Go Player, by Andre Ye10 novembro 2024
How DeepMind's AlphaGo Became the World's Top Go Player, by Andre Ye10 novembro 2024 -
 PDF) The Next Rembrandt Surveils AlphaZero: An AI Lover Story Entangling Machine Cognition10 novembro 2024
PDF) The Next Rembrandt Surveils AlphaZero: An AI Lover Story Entangling Machine Cognition10 novembro 2024 -
 Alpha Scholars10 novembro 2024
Alpha Scholars10 novembro 2024 -
Alpha Kappa Alpha Sorority, Incorporated - Rho Xi Omega Chapter10 novembro 2024

você pode gostar
-
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/d/i/sVEZZsQFKof2R7aFAAgA/instastatistics.jpg) Instastatistics: como ver seguidores do Instagram em tempo real10 novembro 2024
Instastatistics: como ver seguidores do Instagram em tempo real10 novembro 2024 -
 Tonikaku Kawaii Vol.16 - Kenjiro Hata /Japanese Manga Book Comic Japan New10 novembro 2024
Tonikaku Kawaii Vol.16 - Kenjiro Hata /Japanese Manga Book Comic Japan New10 novembro 2024 -
 The Powers of Using A Social Media Influencer For Promotion10 novembro 2024
The Powers of Using A Social Media Influencer For Promotion10 novembro 2024 -
 Cat - Free animals icons10 novembro 2024
Cat - Free animals icons10 novembro 2024 -
Ready Player One Soundtrack (2018), List of Songs10 novembro 2024
-
 Haikyu!! The Neko-Karasu Reunion - Watch on Crunchyroll10 novembro 2024
Haikyu!! The Neko-Karasu Reunion - Watch on Crunchyroll10 novembro 2024 -
 Love, Chunibyo & Other Delusions - Our Works10 novembro 2024
Love, Chunibyo & Other Delusions - Our Works10 novembro 2024 -
 FIFA 18 ratings: Top 100 best player stats ahead of release date, Football, Sport10 novembro 2024
FIFA 18 ratings: Top 100 best player stats ahead of release date, Football, Sport10 novembro 2024 -
 Pastor Holandês - Saiba tudo sobre a raça10 novembro 2024
Pastor Holandês - Saiba tudo sobre a raça10 novembro 2024 -
 GTA RP: o que é e como jogar - Olhar Digital10 novembro 2024
GTA RP: o que é e como jogar - Olhar Digital10 novembro 2024
