8 Advanced parallelization - Deep Learning with JAX
Por um escritor misterioso
Last updated 15 novembro 2024

Using easy-to-revise parallelism with xmap() · Compiling and automatically partitioning functions with pjit() · Using tensor sharding to achieve parallelization with XLA · Running code in multi-host configurations
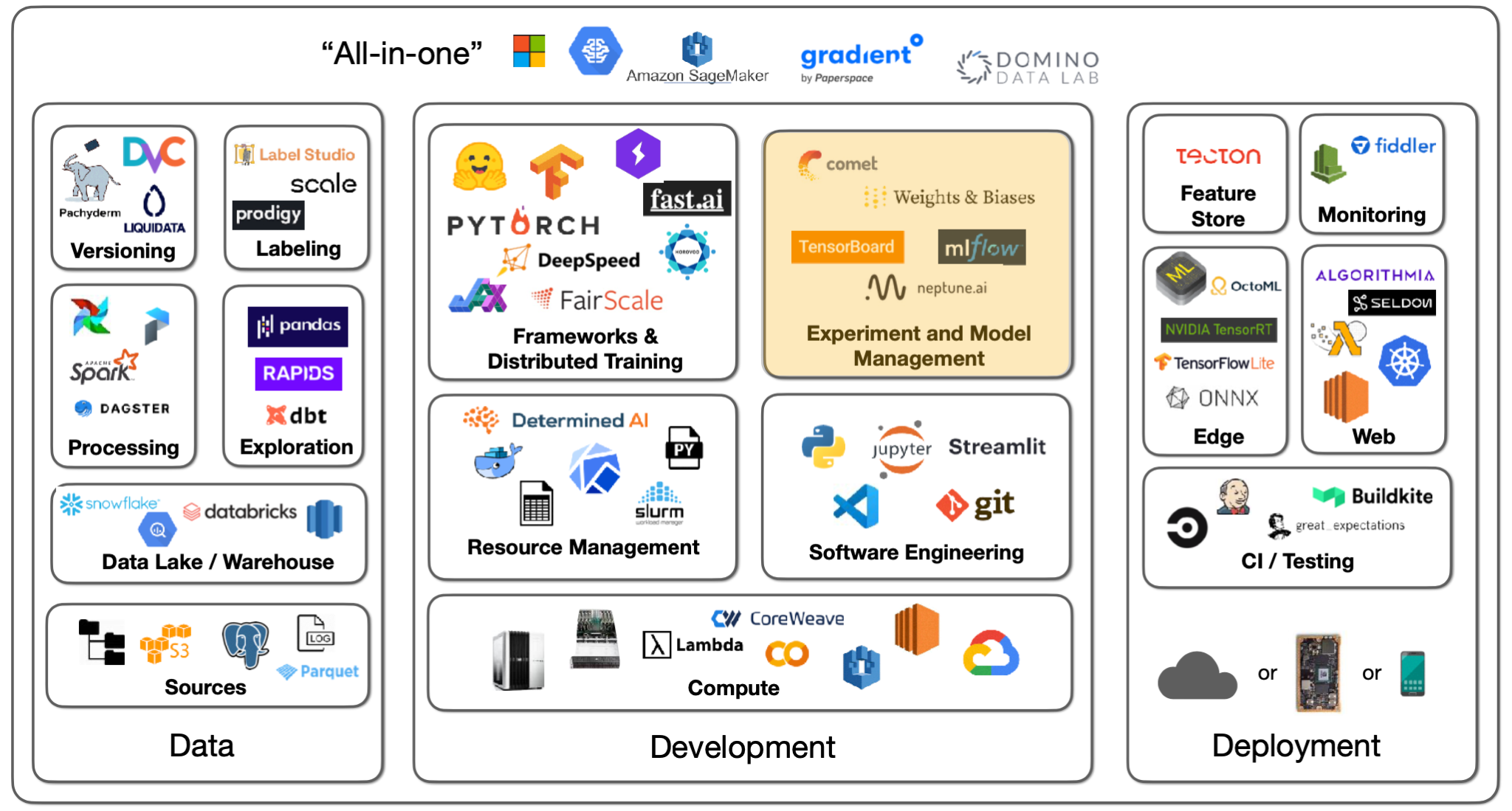
Lecture 2: Development Infrastructure & Tooling - The Full Stack

Data preprocessing for deep learning: Tips and tricks to optimize

Why You Should (or Shouldn't) be Using Google's JAX in 2023
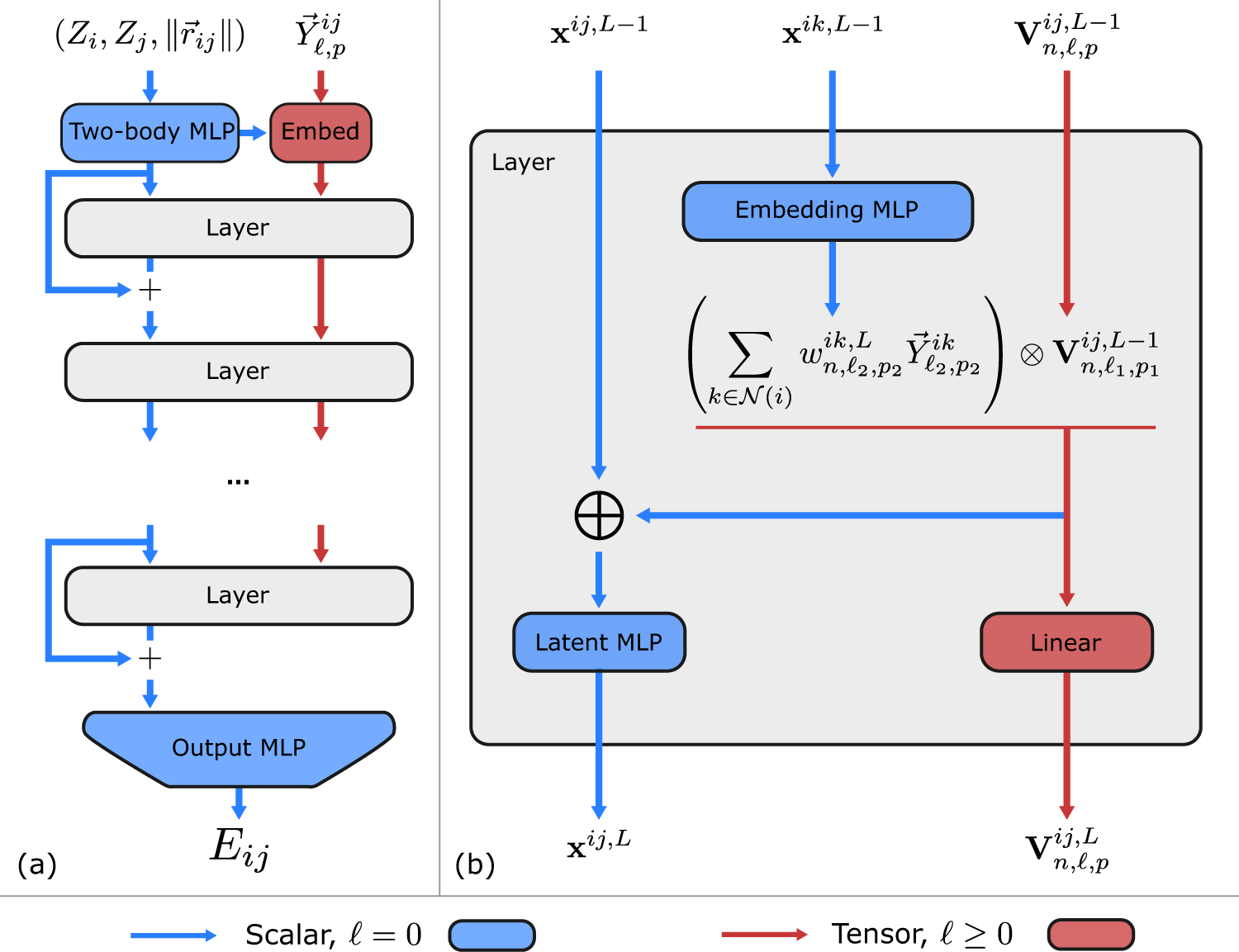
Learning local equivariant representations for large-scale

Dive into Deep Learning — Dive into Deep Learning 1.0.3 documentation

Grigory Sapunov on LinkedIn: Deep Learning with JAX
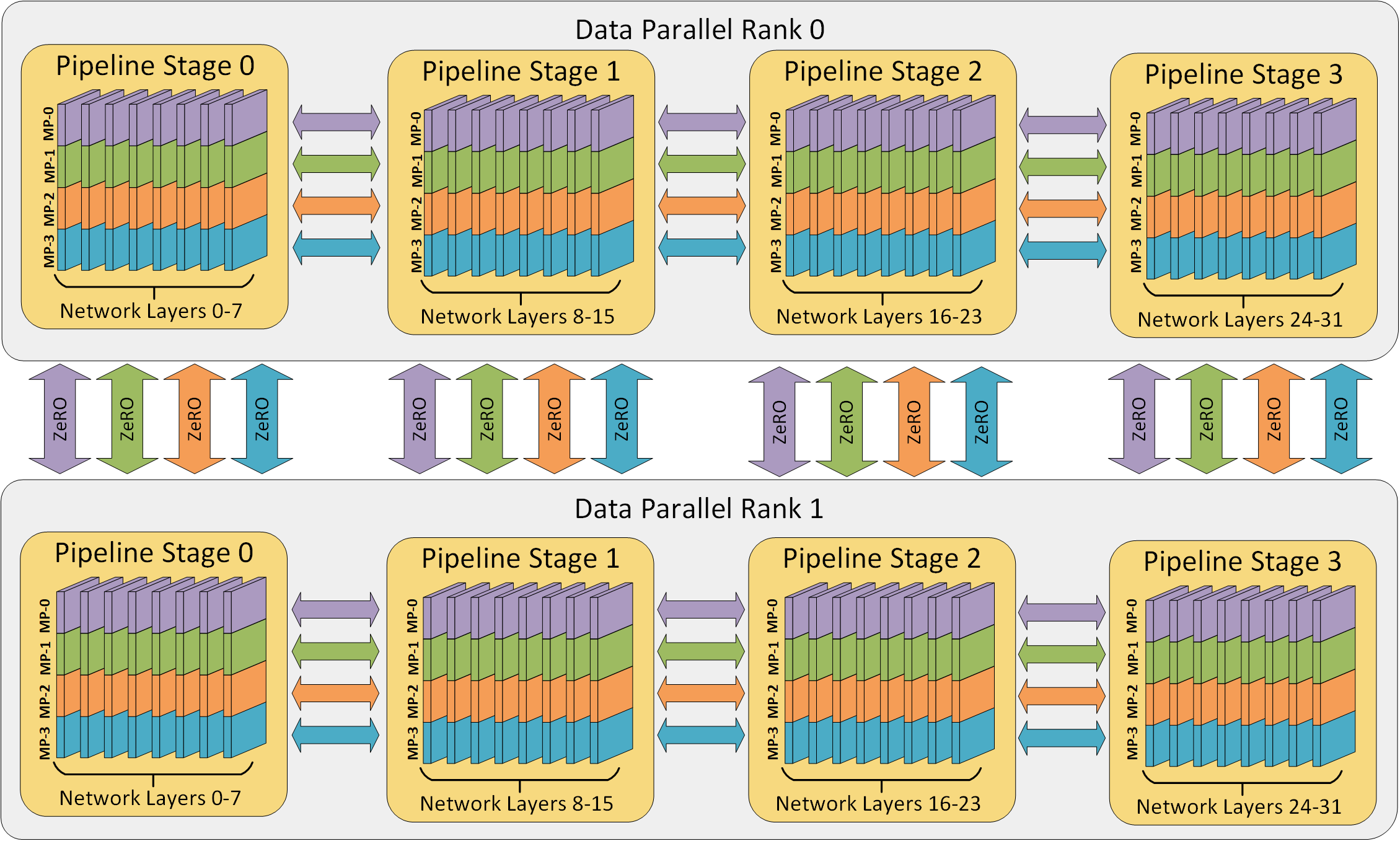
A Brief Overview of Parallelism Strategies in Deep Learning
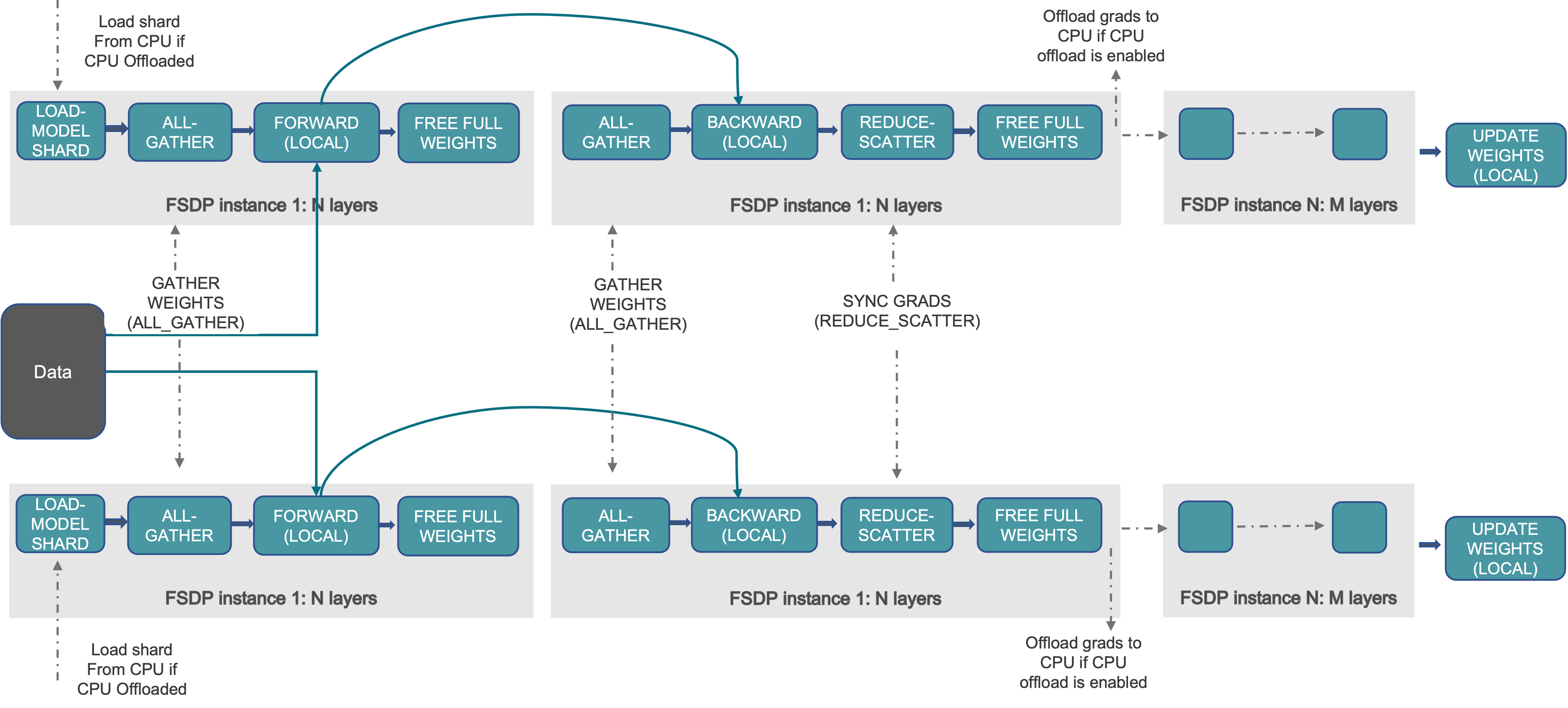
Introducing PyTorch Fully Sharded Data Parallel (FSDP) API

Compiler Technologies in Deep Learning Co-Design: A Survey

Convolution hierarchical deep-learning neural network (C-HiDeNN
GitHub - che-shr-cat/JAX-in-Action: Notebooks for the JAX in
Why You Should (or Shouldn't) be Using Google's JAX in 2023
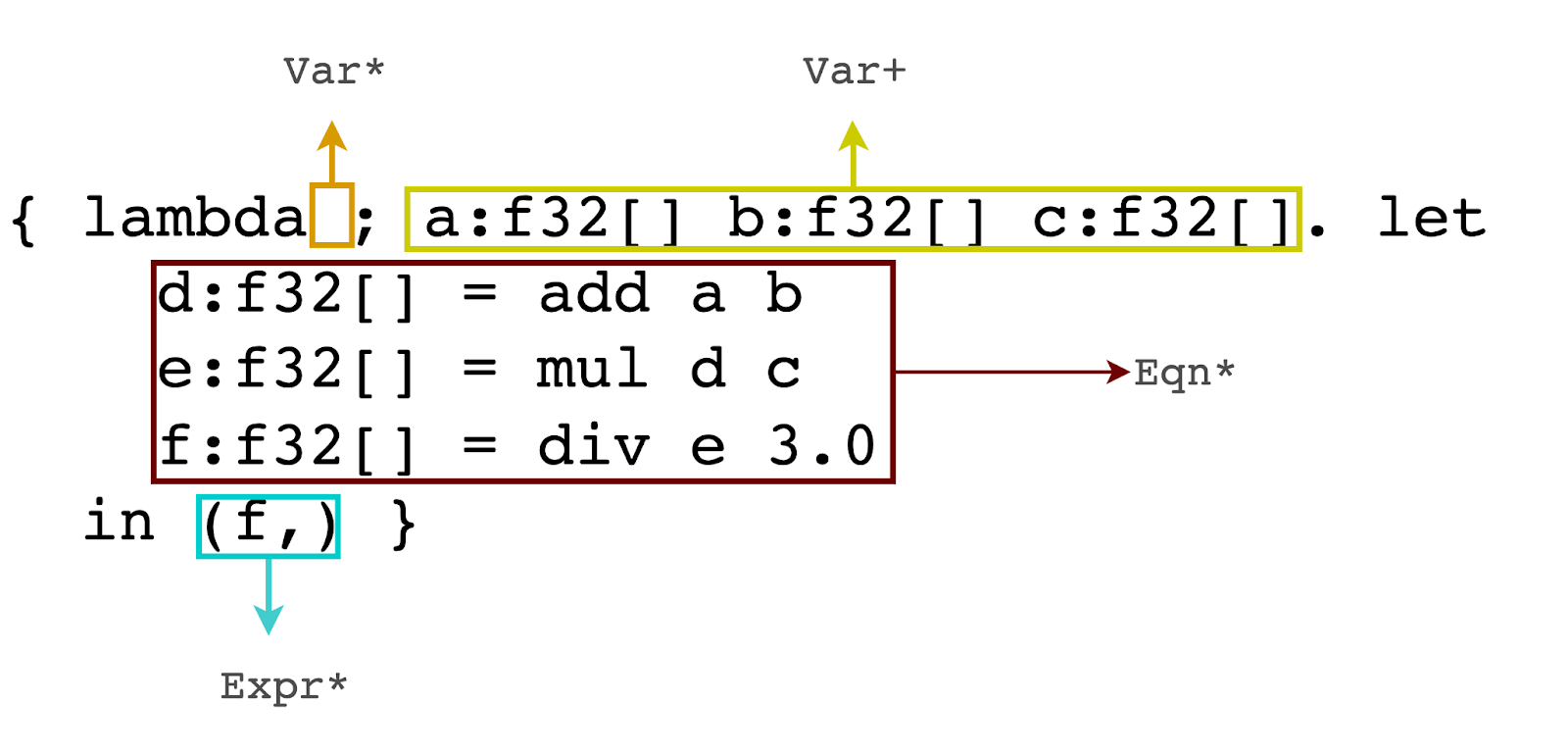
Learn JAX in 2023: Part 2 - grad, jit, vmap, and pmap
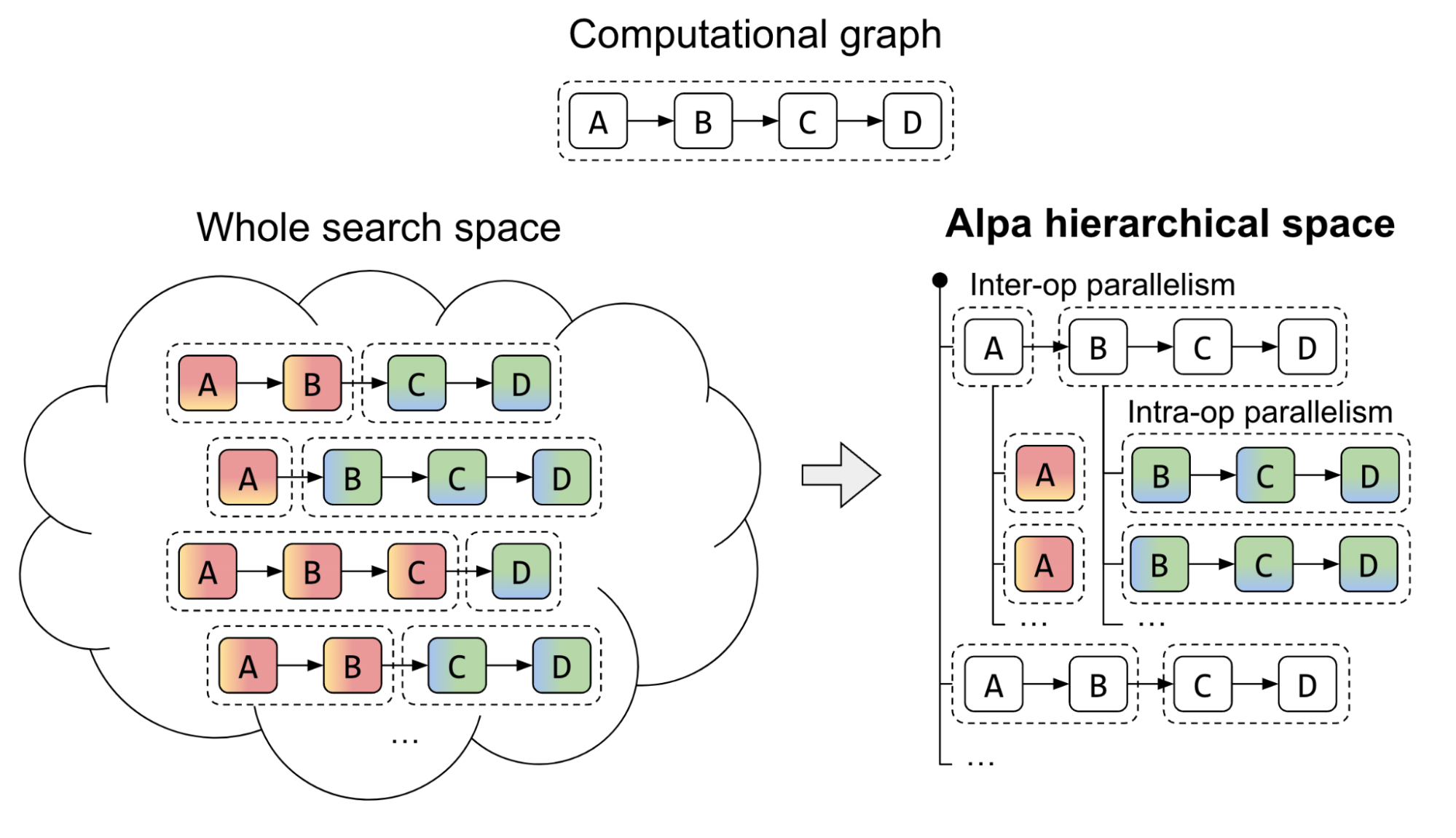
Efficiently Scale LLM Training Across a Large GPU Cluster with
Recomendado para você
-
1bhk for rent.. - For Rent: Houses & Apartments - 175055698715 novembro 2024
-
 Program Book - Gershwin & Bernstein by Chicago Symphony15 novembro 2024
Program Book - Gershwin & Bernstein by Chicago Symphony15 novembro 2024 -
demo/docs/03_sparkLoad2StarRocks.md at master · StarRocks/demo15 novembro 2024
-
 Income tax basics15 novembro 2024
Income tax basics15 novembro 2024 -
_exploring-the-scp-foundation-scp-2951-10000-years-preview-hqdefault.jpg) Exploring the SCP Foundation: SCP-2951 - 10,000 Years from scp15 novembro 2024
Exploring the SCP Foundation: SCP-2951 - 10,000 Years from scp15 novembro 2024 -
Double Ball Valve, PDF, Valve15 novembro 2024
-
Education Catering jobs15 novembro 2024
-
 Program Book - CSO at Wheaton: The Rite of Spring & Kavakos by Chicago Symphony Orchestra - Issuu15 novembro 2024
Program Book - CSO at Wheaton: The Rite of Spring & Kavakos by Chicago Symphony Orchestra - Issuu15 novembro 2024 -
 Builder Floor for Rent Near Tvisimat Toddlers, Phase 2, Sector 57, Gurgaon 410+ Rental Builder Floors Near Tvisimat Toddlers, Phase 2, Sector 57, Gurgaon15 novembro 2024
Builder Floor for Rent Near Tvisimat Toddlers, Phase 2, Sector 57, Gurgaon 410+ Rental Builder Floors Near Tvisimat Toddlers, Phase 2, Sector 57, Gurgaon15 novembro 2024 -
 D-4666/SCP-10000-2-A, Wiki15 novembro 2024
D-4666/SCP-10000-2-A, Wiki15 novembro 2024


você pode gostar
-
 Jogos de Maquiar a Barbie no Jogos 36015 novembro 2024
Jogos de Maquiar a Barbie no Jogos 36015 novembro 2024 -
 Chained Echoes Review (Switch)15 novembro 2024
Chained Echoes Review (Switch)15 novembro 2024 -
 Dvd Filme: Resident Evil - A Ilha Da Morte (2023) Dub E Leg15 novembro 2024
Dvd Filme: Resident Evil - A Ilha Da Morte (2023) Dub E Leg15 novembro 2024 -
/i.s3.glbimg.com/v1/AUTH_bc8228b6673f488aa253bbcb03c80ec5/internal_photos/bs/2021/9/A/zdYcYqQKqFCj9kBOatjA/fifa-21-messi-99-perfeito.png) FIFA 21: Messi recebe carta perfeita como a primeira no PSG, fifa15 novembro 2024
FIFA 21: Messi recebe carta perfeita como a primeira no PSG, fifa15 novembro 2024 -
 Kingdom: Where to Watch and Stream Online15 novembro 2024
Kingdom: Where to Watch and Stream Online15 novembro 2024 -
 Imagens vazadas do Galaxy S23 Ultra e S23 Plus mostram novas cores – Tecnoblog15 novembro 2024
Imagens vazadas do Galaxy S23 Ultra e S23 Plus mostram novas cores – Tecnoblog15 novembro 2024 -
 ROBLOX RAINBOW FRIENDS 4 PACK NEON PURPLE ORANGE GREEN BLUE SERIES15 novembro 2024
ROBLOX RAINBOW FRIENDS 4 PACK NEON PURPLE ORANGE GREEN BLUE SERIES15 novembro 2024 -
 Two or more players Poki games APK for Android Download15 novembro 2024
Two or more players Poki games APK for Android Download15 novembro 2024 -
 Sporting Clube de Portugal15 novembro 2024
Sporting Clube de Portugal15 novembro 2024 -
 Jogo de Boliche - LDM15 novembro 2024
Jogo de Boliche - LDM15 novembro 2024